Hyperparams tuning of Reinforcement Learning in Tensorflow
Deep-learning ·Hyperparams tuning is an essential step towards optimal performance of your neural network. Instead of lowly efficient tuning by hand, a systematic and clustered solution is far away efficient and consistent. This blog shows how to use TensorBoard Hyperparam plugin to search optimal hyperparams.
Hyperparams
Hyperparams are the predefined skeleton of your learning model. Contrasted with weights of neurons, they are fixed during training process.
In RL, the typical hyperparams are: optimizer, learning rate, momentum, discount of reward, discount of GAE, batch size and etc. There are also more important hyperparams for each RL algorithms. For example: extra hyperparams in PPO:
- clip ratio (0.1, 0.2, 0.3)
- clip range of value
- gradient norm (usually 0.5)
- entropy coefficient (1e-3, 1e-4 , etc, usually small)
- value coefficient (usually 0.5)
The common values of each hyperparams are a good start point. But you should feel free to modify them.
Metrics
For each cluster of hyperparams, there should be evaluation metrics to select the optimal one. In RL, the mean of rewards is definitely needed. Apart from it, I also use explained variance of predicted values to evaluate how good the value network it is. Depending on the RL problem, average length of the trajectory is also useful.
In summary, metrics could include:
- rewards
- explained variance between predicted values and return
- average length of trajectories
Skeleton
from tensorboard.plugins.hparams import api as hp
hp_summary_dir = "logs/" + current_time + "/hparam_tuning"
HP_LR = hp.HParam("lr", hp.Discrete([7e-4, 3e-4, 7e-5, 3e-5]))
HP_CLIP = hp.HParam("clip", hp.Discrete([0.3, 0.2, 0.1]))
HP_ENTROPY_COEF = hp.HParam("entropy_coef", hp.Discrete([1e-5, 1e-4, 1e-3, 1e-2]))
HP_GRADIENT_NORM = hp.HParam("gradient_norm", hp.Discrete([0.5, 1.0, 10.0]))
# Add top level hparams structure. Describe params and metrics going to be tracked in training.
with tf.summary.create_file_writer(hp_summary_dir).as_default():
hp.hparams_config(
hparams=[HP_LR, HP_CLIP, HP_ENTROPY_COEF, HP_GRADIENT_NORM],
metrics=[hp.Metric("rewards", display_name="rewards")],
)
times = 0
for times in range(search_times):
# Here I use random search. Grid search or more adavanced distribution search also works.
lr = random.choice(HP_LR.domain.values)
clip = random.choice(HP_CLIP.domain.values)
ent_coef = random.choice(HP_ENTROPY_COEF.domain.values)
grad_norm = random.choice(HP_GRADIENT_NORM.domain.values)
hparams = {
HP_LR: lr,
HP_CLIP: clip,
HP_ENTROPY_COEF: ent_coef,
HP_GRADIENT_NORM: grad_norm,
}
hp_summary_writer = tf.summary.create_file_writer(
hp_summary_dir + "/run-{}".format(times)
)
# Record current hparams in this training
with hp_summary_writer.as_default():
hp.hparams(hparams)
train(
hparams,
hp_summary_writer,
)
times += 1
def train(hparams, hp_summary_writer):
""" Your main training function"""
<Your learning process ..>
# Record metrics
with hp_summary_writer.as_default():
tf.summary.scalar("rewards", np.mean(cumulative_rew), step=i)
Hands-on
Here is a quick try-out with previous skeleton.
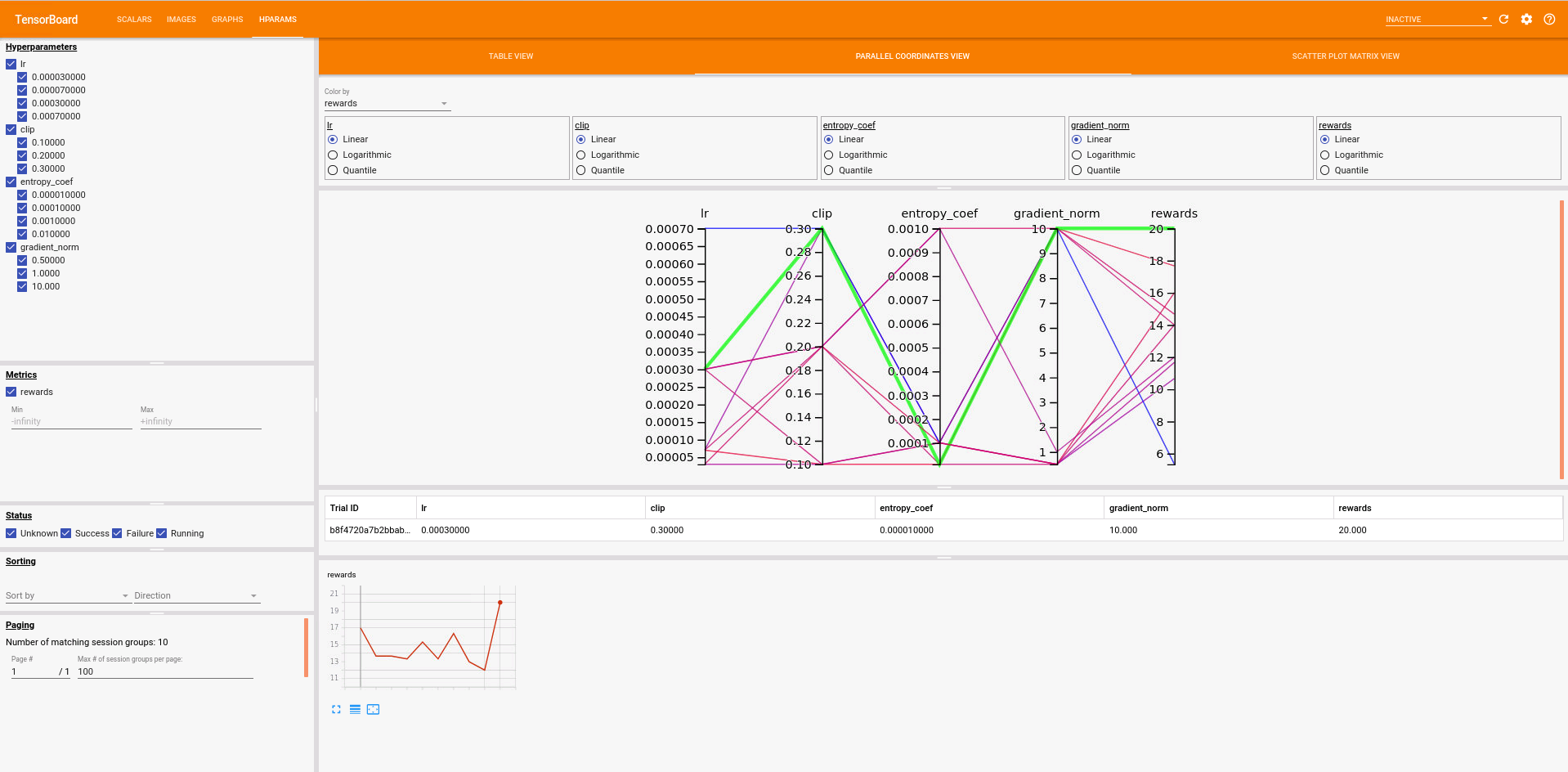
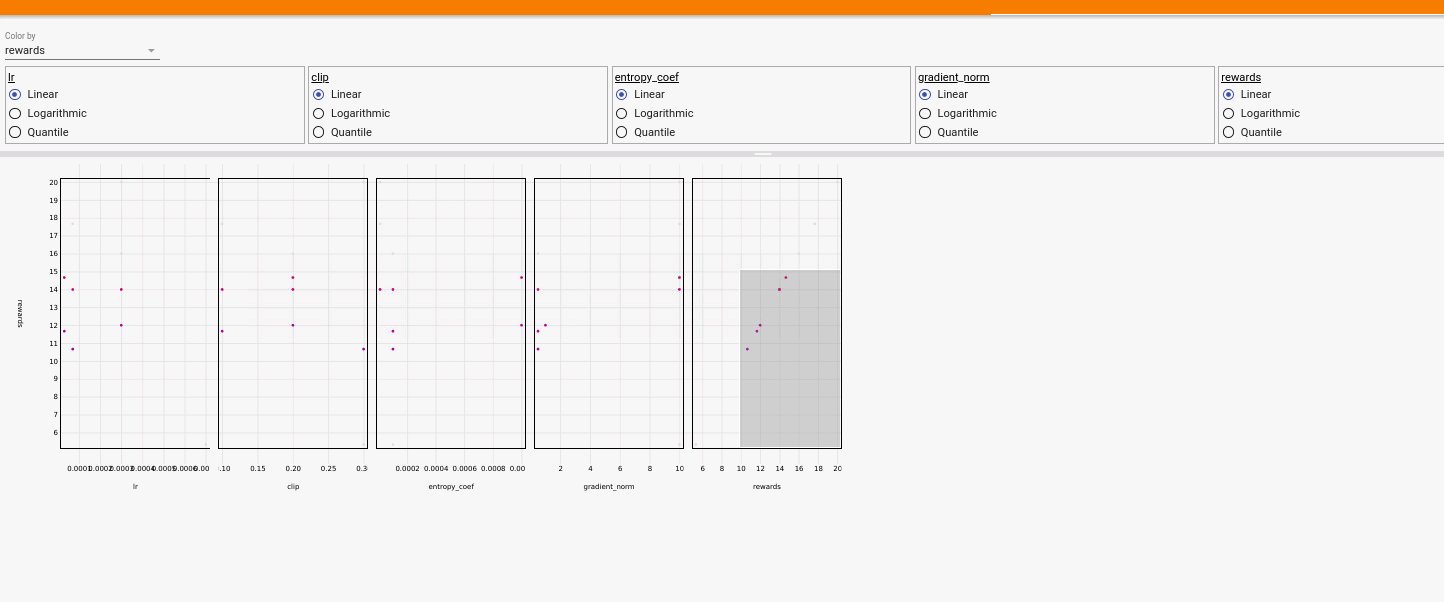
In the graph, it is much easier to shrink the optimal search range or even spot the optimal values for each hyperparam.